
2025春秋杯冬季赛
菜鸟第一次打这种公开赛,感觉被橄榄了,第二天两个pyjail是一点办法都没有啊。。。
听C3师傅说这还不算是上强度的
而且准备转型Web却只做出来一个签到属于是。。有点丢人了
还是要多练,下次努力不啃Misc老底
MISC
简单算术:
根据提示,想想异或,直接尝试Cyberchef一把梭
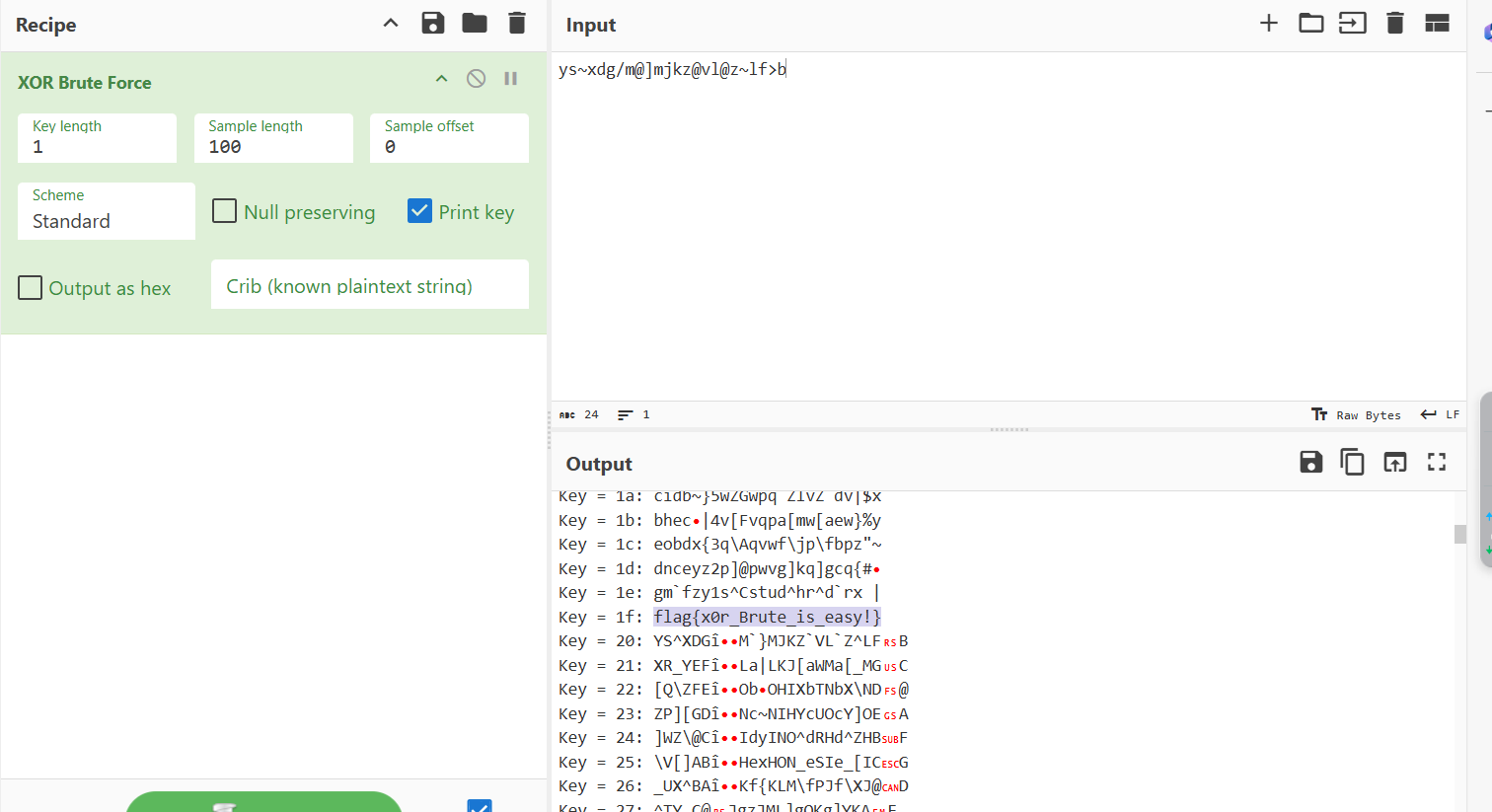
See anything in these pics?
附件给了一个压缩包和一张阿兹特克码
解析得到
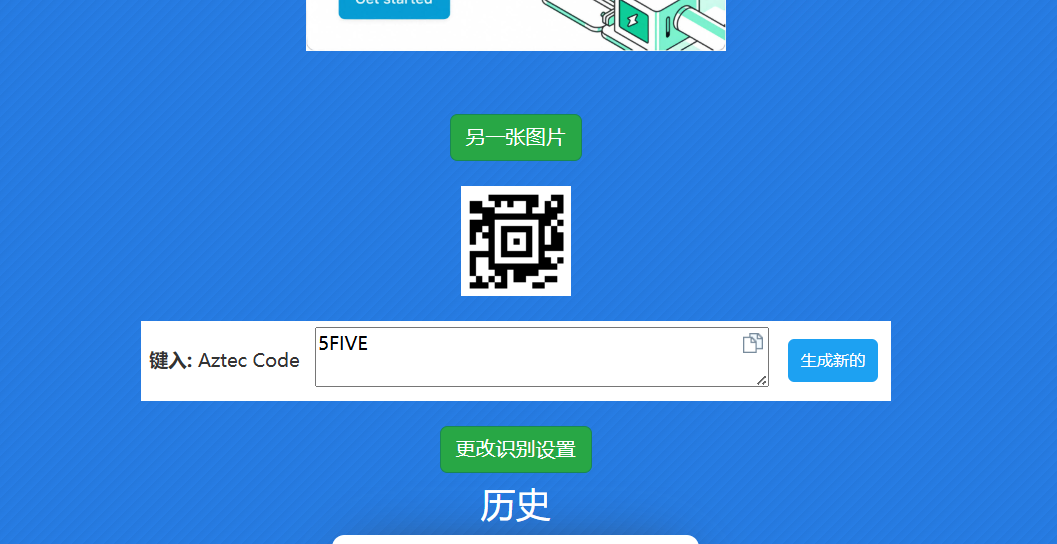
怀疑是压缩包的密码,带入解压压缩包,解压成功,得到一张jpg
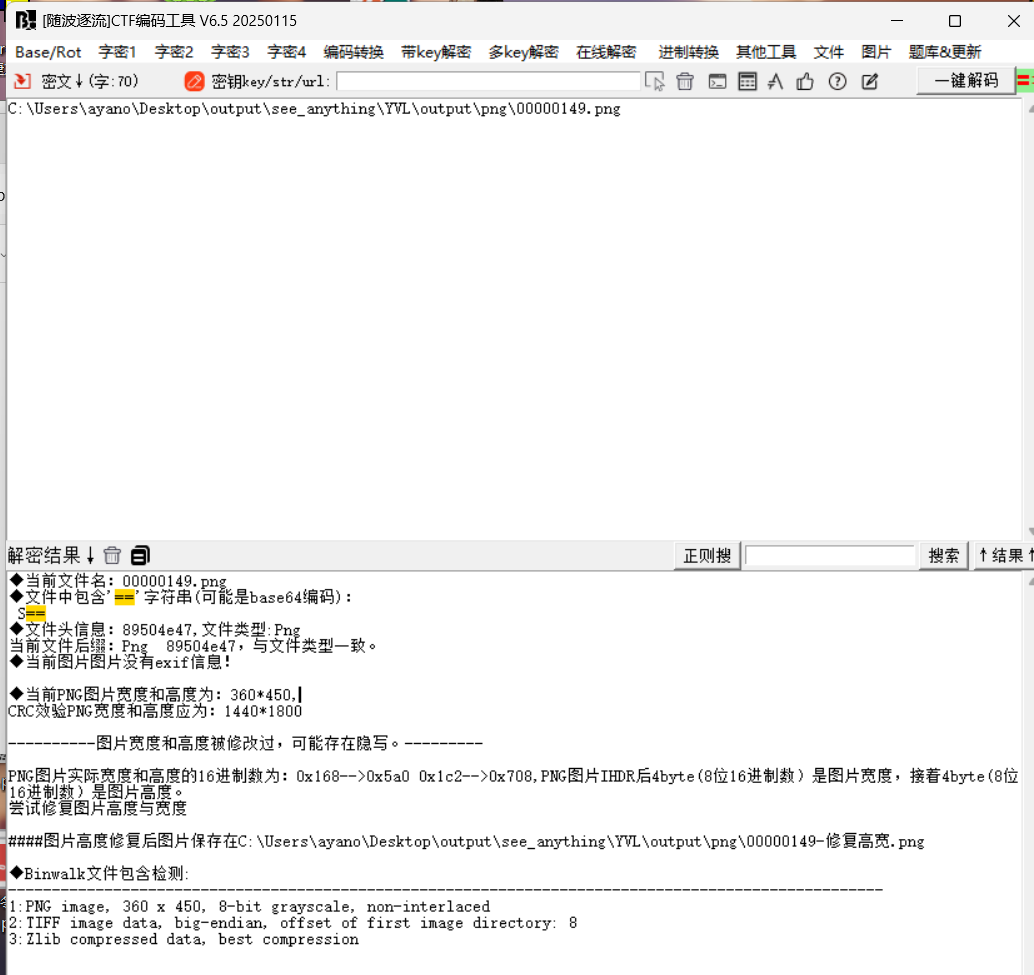
看图片结合提示(图片不止两张)猜测一共有三张图,打开010查一下,发现PNG头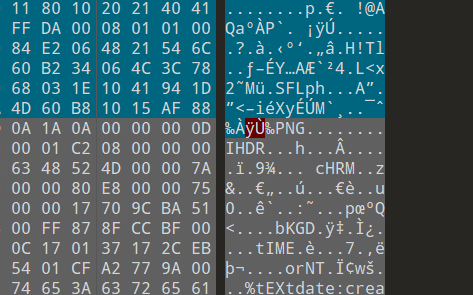
foremost提取一下发现是全黑的,猜测是crc校验错误,打开010发现报错检验猜想,最后随波逐流直接出(也可以直接随波逐流一把梭)

压力大,写个脚本吧
先试着解压几个包,把给的密文base64解码后是FGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFG
然后发现后面几个包的密文都是一样的,写个脚本直接爆
import zipfile
import re
zipname = "C:\\Users\\ayano\\Desktop\\output\\zip_100\\zip_99.zip"
while True:
if zipname != "C:\\Users\\ayano\\Desktop\\output\\zip_100\\zip_1.zip":
ts1 = zipfile.ZipFile(zipname)
passwd =b'FGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFGFG'
ts1.extractall("C:\\Users\\ayano\\Desktop\\output\\zip_100\\",pwd=passwd)
zipname = "C:\\Users\\ayano\\Desktop\\output\\zip_100\\"+ts1.namelist()[0]
else:
print("find")结果发现第95包密码换了。解压显示失败,那么直接获取txt的内容解码后解压压缩包。
import zipfile
import os
import base64
def decode_password(file_path):
with open(file_path, 'r') as f:
encoded_password = f.read().strip()
decoded_password = base64.b64decode(encoded_password).decode('utf-8')
return decoded_password
def extract_zip(zip_file, password, extract_to):
try:
with zipfile.ZipFile(zip_file) as zf:
zf.extractall(path=extract_to, pwd=password.encode())
print(f"解压成功: {zip_file} 到 {extract_to}")
return zf.namelist()
except (zipfile.BadZipFile, RuntimeError) as e:
print(f"解压失败: {zip_file}, 错误: {e}")
return []
def recursive_extract(start_number=99,parent_dir='C:\\Users\\ayano\\Desktop\\output\\zip_100\\'):
current_number = start_number
while True:
zip_filename = f"C:\\Users\\ayano\\Desktop\\output\\zip_100\\zip_{current_number}.zip"
password_filename = f"C:\\Users\\ayano\\Desktop\\output\\zip_100\\password_{current_number}.txt"
if not os.path.exists(zip_filename):
print(f"文件不存在: {zip_filename}")
break
if not os.path.exists(password_filename):
print(f"密码文件不存在: {password_filename}")
break
password = decode_password(password_filename)
extracted_files = extract_zip(zip_filename, password,parent_dir)
if not extracted_files:
break
next_zip_file = None
for extracted_file in extracted_files:
if extracted_file.endswith('.zip'):
next_zip_file = extracted_file
break
if next_zip_file is None:
break
current_number -= 1
if __name__ == "__main__":
recursive_extract()解码后得到hint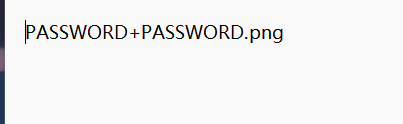
应该是让我们把每个压缩包的密码解码后组成hex码产生一个png图片
根据我们第一个密码FG…,显然不是文件头的格式,那么从0开始到99提取文件内容
import os
import base64
def decode_password(file_path):
with open(file_path, 'r') as f:
encoded_password = f.read().strip()
decoded_password = base64.b64decode(encoded_password).decode('utf-8')
return decoded_password
def extract_decoded_passwords(start_number=0, output_file='decoded_passwords.txt'):
with open(output_file, 'w') as output_f:
current_number = start_number
while True:
password_filename = f"C:\\Users\\ayano\\Desktop\\output\\zip_100\\password_{current_number}.txt"
if not os.path.exists(password_filename):
print(f"密码文件不存在: {password_filename}")
break
decoded_password = decode_password(password_filename)
output_f.write(f"{decoded_password}")
print(f"密码_{current_number} 解码并保存。")
current_number += 1
if __name__ == "__main__":
extract_decoded_passwords(start_number=0, output_file='C:\\Users\\ayano\\Desktop\\1.txt')最终得到的在010中粘贴为hex码,得到一个二维码,扫一下

Infinity
首先看提示是不知道有什么用的
拿到一张png,用010查一下看到zip头
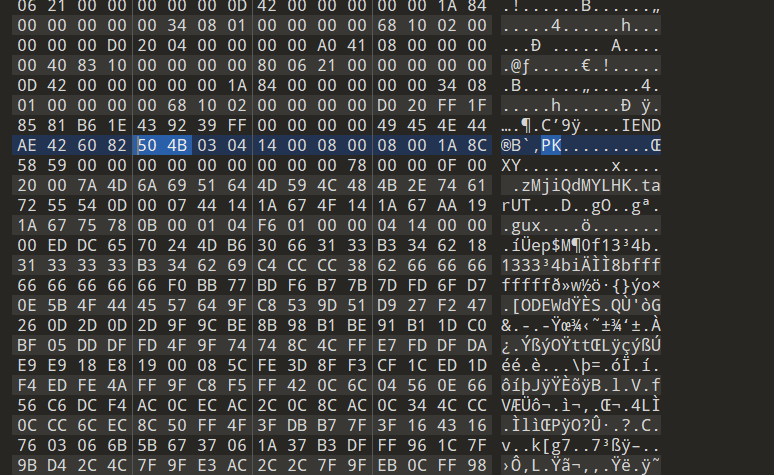
foremost提取一下
得到一个压缩包,在解压几次后发现是个嵌套的压缩包
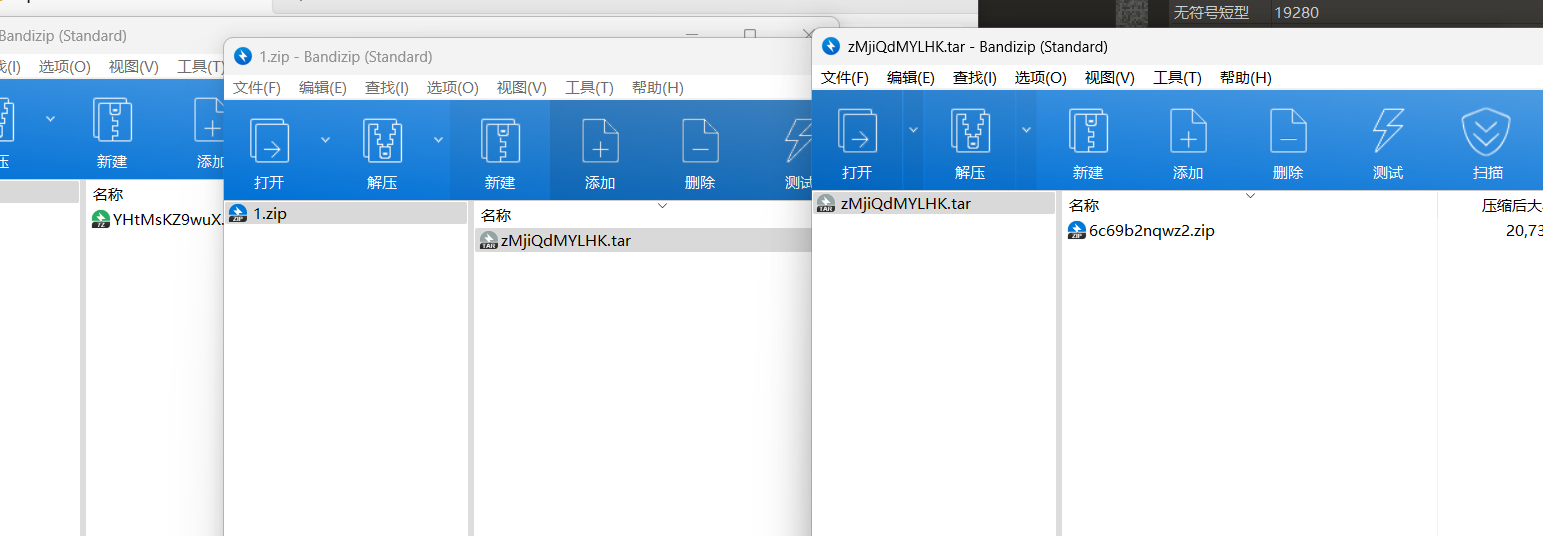 一共有7z,tar,zip三种类型的压缩包
一共有7z,tar,zip三种类型的压缩包
同时注意到文件名有点可疑,留意一下,可能后续要用
脚本:
import os
import zipfile
import tarfile
import py7zr
import shutil
def extract_zip(zip_path, extract_dir):
"""解压zip文件"""
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
zip_ref.extractall(extract_dir)
return zip_ref.namelist() # 返回解压出来的文件列表
def extract_tar(tar_path, extract_dir):
"""解压tar文件"""
with tarfile.open(tar_path, 'r') as tar_ref:
tar_ref.extractall(extract_dir)
return tar_ref.getnames() # 返回解压出来的文件列表
def extract_7z(archive_path, extract_dir):
"""解压7z文件"""
with py7zr.SevenZipFile(archive_path, mode='r') as archive_ref:
archive_ref.extractall(extract_dir)
return archive_ref.getnames() # 返回解压出来的文件列表
def handle_compressed_file(file_path, extract_dir, output_txt):
"""处理压缩包文件:解压并记录文件名(去掉后缀并连接)"""
if file_path.endswith('.zip'):
extracted_files = extract_zip(file_path, extract_dir)
elif file_path.endswith('.tar'):
extracted_files = extract_tar(file_path, extract_dir)
elif file_path.endswith('.7z'):
extracted_files = extract_7z(file_path, extract_dir)
else:
print(f"不支持的压缩格式:{file_path}")
return []
# 记录去掉后缀并连接的文件名
with open(output_txt, 'a') as output_file:
for file_name in extracted_files:
name_without_extension = os.path.splitext(file_name)[0] # 去掉后缀
output_file.write(f"{name_without_extension}\n")
return extracted_files
def process_zip(zip_path, extract_dir, output_txt):
"""处理zip文件并递归解压其中的压缩包"""
# 解压当前zip文件并返回解压后的文件列表
extracted_files = extract_zip(zip_path, extract_dir)
for extracted_file in extracted_files:
extracted_file_path = os.path.join(extract_dir, extracted_file)
if os.path.isdir(extracted_file_path):
continue # 跳过目录
# 如果解压出来的是压缩包,再进行递归处理
if extracted_file.endswith(('.zip', '.tar', '.7z')):
# 解压嵌套压缩包并处理
handle_compressed_file(extracted_file_path, extract_dir, output_txt)
# 如果是嵌套的压缩包,再递归调用
if extracted_file.endswith('.zip'):
process_zip(extracted_file_path, extract_dir, output_txt)
elif extracted_file.endswith('.tar'):
process_tar(extracted_file_path, extract_dir, output_txt)
elif extracted_file.endswith('.7z'):
process_7z(extracted_file_path, extract_dir, output_txt)
else:
handle_compressed_file(extracted_file_path, extract_dir, output_txt)
# 删除当前处理的压缩包
if zip_path.endswith('.zip'):
os.remove(zip_path)
def process_tar(tar_path, extract_dir, output_txt):
"""处理tar文件并递归解压其中的压缩包"""
extracted_files = extract_tar(tar_path, extract_dir)
for extracted_file in extracted_files:
extracted_file_path = os.path.join(extract_dir, extracted_file)
if os.path.isdir(extracted_file_path):
continue
if extracted_file.endswith(('.zip', '.tar', '.7z')):
handle_compressed_file(extracted_file_path, extract_dir, output_txt)
if extracted_file.endswith('.zip'):
process_zip(extracted_file_path, extract_dir, output_txt)
elif extracted_file.endswith('.tar'):
process_tar(extracted_file_path, extract_dir, output_txt)
elif extracted_file.endswith('.7z'):
process_7z(extracted_file_path, extract_dir, output_txt)
# 删除当前处理的压缩包
if tar_path.endswith('.tar'):
os.remove(tar_path)
def process_7z(archive_path, extract_dir, output_txt):
"""处理7z文件并递归解压其中的压缩包"""
extracted_files = extract_7z(archive_path, extract_dir)
for extracted_file in extracted_files:
extracted_file_path = os.path.join(extract_dir, extracted_file)
if os.path.isdir(extracted_file_path):
continue
if extracted_file.endswith(('.zip', '.tar', '.7z')):
handle_compressed_file(extracted_file_path, extract_dir, output_txt)
if extracted_file.endswith('.zip'):
process_zip(extracted_file_path, extract_dir, output_txt)
elif extracted_file.endswith('.tar'):
process_tar(extracted_file_path, extract_dir, output_txt)
elif extracted_file.endswith('.7z'):
process_7z(extracted_file_path, extract_dir, output_txt)
# 删除当前处理的压缩包
if archive_path.endswith('.7z'):
os.remove(archive_path)
def main():
zip_path = r'C:\Users\ayano\Desktop\output\Infinity\output\zip\1.zip'
extract_dir = r'C:\Users\ayano\Desktop\output\Infinity\output\zip\extracted'
output_txt = r'C:\Users\ayano\Desktop\output\Infinity\output\zip\output.txt'
if not os.path.exists(extract_dir):
os.makedirs(extract_dir)
# 开始处理压缩包
with open(output_txt, 'w') as output_file:
output_file.write("")
process_zip(zip_path, extract_dir, output_txt)
if __name__ == "__main__":
main()再对提出来的文件名做两种处理
def reverse_file_names(input_txt, output_txt):
"""读取文件名并将其从后往前连接"""
with open(input_txt, 'r') as infile:
file_names = infile.readlines()
# 去掉换行符并从后往前连接
reversed_file_names = [name.strip() for name in reversed(file_names)]
# 将连接后的文件名写入新文件
with open(output_txt, 'w') as outfile:
outfile.write("连接后的文件名(从后往前):\n")
outfile.write("".join(reversed_file_names)) # 使用空格连接文件名
def remove_newlines_and_connect(input_txt, output_txt):
"""读取文件名并去掉换行符,连接所有文件名"""
with open(input_txt, 'r') as infile:
# 读取所有行并去掉换行符
file_names = infile.read().splitlines()
# 将文件名用空格连接
connected_file_names = "".join(file_names)
# 将连接后的文件名写入新文件
with open(output_txt, 'w') as outfile:
outfile.write("连接后的文件名(去掉换行符):\n")
outfile.write(connected_file_names) # 直接写入连接后的字符串
def main():
input_txt = r'C:\Users\ayano\Desktop\output\Infinity\output\zip\output.txt'
output1_txt = r'C:\Users\ayano\Desktop\output\Infinity\output\zip\output_reversed.txt'
output2_txt = r'C:\Users\ayano\Desktop\output\Infinity\output\zip\output_simple.txt'
reverse_file_names(input_txt, output1_txt)
remove_newlines_and_connect(input_txt, output2_txt)
if __name__ == "__main__":
main()根据提示BASE58-Ripple、SM4-ECB
先后尝试顺序的和逆序的
最后逆序的得到以下
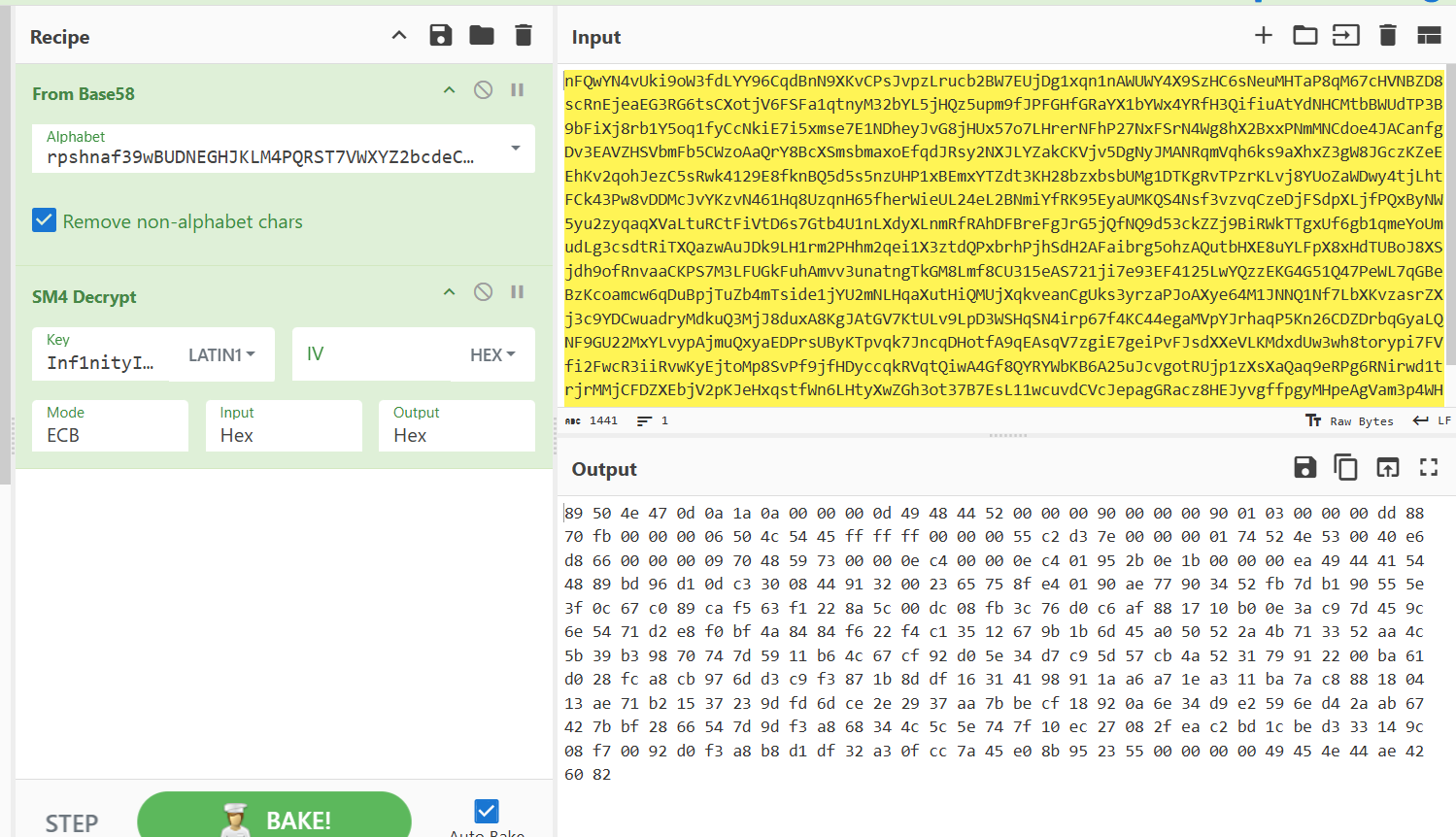
看一眼是png的文件头,在010以16进制粘贴得到一张图片

在谷歌搜图后判断出是 DataMatrix码
在线工具解决 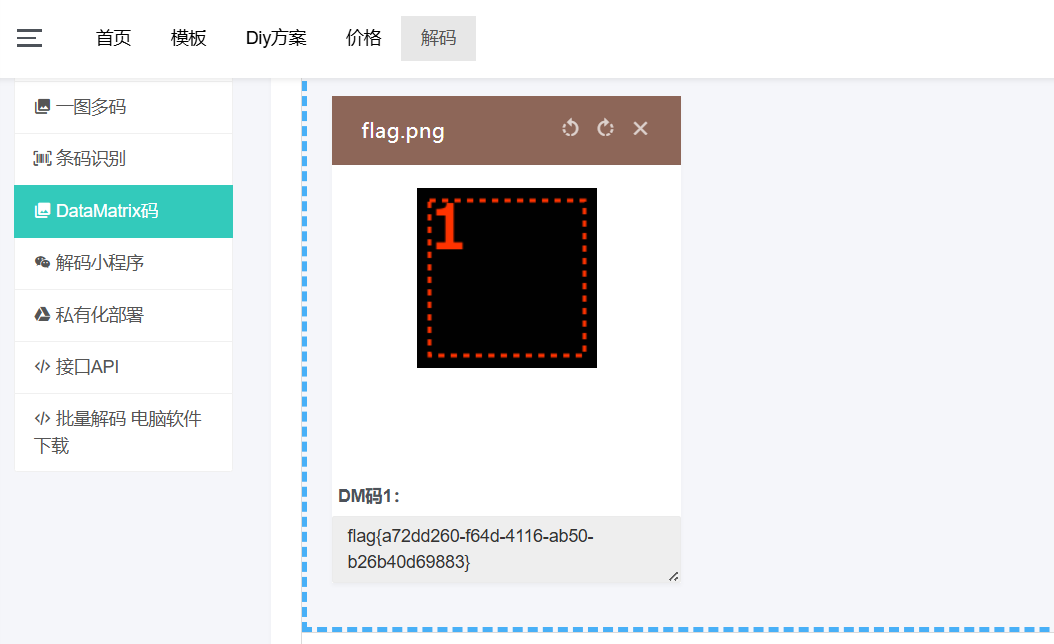
音频的秘密
解压得到一个wav文件
根据提示deepsound和弱口令
试一下123?
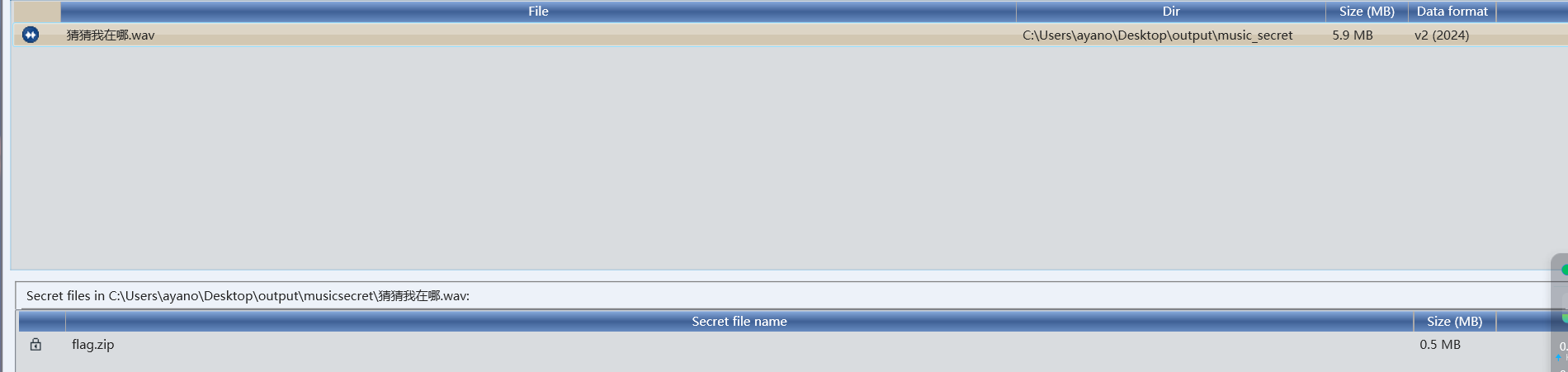
运气比较好直接出来了
提取zip后发现需要密码打开
在010查过之后发现是真加密

没有提示,直接尝试明文爆破,已知png文件头,以这个为明文开始爆
echo 89504E470D0A1A0A0000000D49484452 | xxd -r -ps > png_header
bkcrack -C flag.zip -c flag.png -p png_header -o 0然后得到密钥 29d29517 0fa535a9 abc67696
bkcrack -C flag.zip -c flag.png -k 29d29517 0fa535a9 abc67696 -d flag.png得到flag.png
 通过stegsolve看一下有没有lsb隐写
通过stegsolve看一下有没有lsb隐写
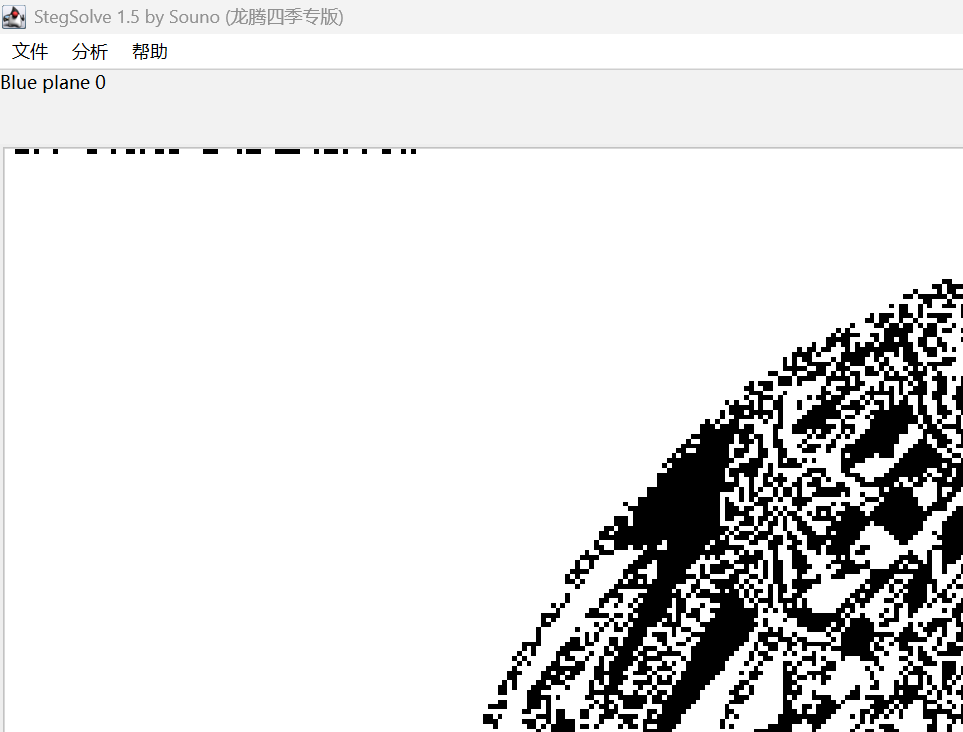
左上角一看肯定有lsb稳了,zsteg一跑

WEB
easy_flask
根据提示想想flask,应该是SSTI漏洞
先试着打一下,看看有没有绕过
{{ config.__class__.__init__.__globals__['os'].popen('ls').read() }}
直接爆了,那就ls换cat flag解决
