
从N1Junoir探究各种环境下的base64处理安全性
探究base64的安全性
前段时间打N1Junior遇到一题利用了Python和Linux对base64 padding的处理差异来绕过
当时是乱尝试无意中就试出来了,现在想想其实如果看看源码可能事情会简单很多吧。。
Python
调试之后可以看到这里
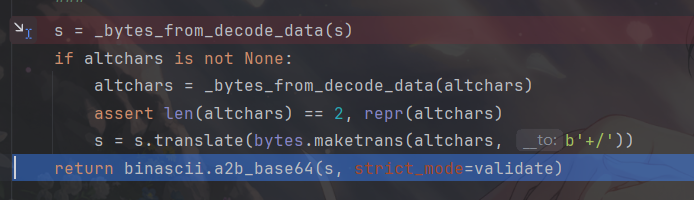
def b64decode(s, altchars=None, validate=False):
"""Decode the Base64 encoded bytes-like object or ASCII string s.
Optional altchars must be a bytes-like object or ASCII string of length 2
which specifies the alternative alphabet used instead of the '+' and '/'
characters.
The result is returned as a bytes object. A binascii.Error is raised if
s is incorrectly padded.
If validate is False (the default), characters that are neither in the
normal base-64 alphabet nor the alternative alphabet are discarded prior
to the padding check. If validate is True, these non-alphabet characters
in the input result in a binascii.Error.
For more information about the strict base64 check, see:
https://docs.python.org/3.11/library/binascii.html#binascii.a2b_base64
"""
s = _bytes_from_decode_data(s)
if altchars is not None:
altchars = _bytes_from_decode_data(altchars)
assert len(altchars) == 2, repr(altchars)
s = s.translate(bytes.maketrans(altchars, b'+/'))
return binascii.a2b_base64(s, strict_mode=validate)先跟进_bytes_from_decode_data这个函数看两眼
def _bytes_from_decode_data(s):
if isinstance(s, str):
try:
return s.encode('ascii')
except UnicodeEncodeError:
raise ValueError('string argument should contain only ASCII characters')
if isinstance(s, bytes_types):
return s
try:
return memoryview(s).tobytes()
except TypeError:
raise TypeError("argument should be a bytes-like object or ASCII "
"string, not %r" % s.__class__.__name__) from None这里其实就是对解码字符的判断,必须是ASCII字符,其他没什么新奇的
最后走到这个函数
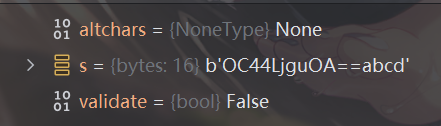
并且可以发现一般的解码下采用的都是非strict的模式
def a2b_base64(*args, **kwargs): # real signature unknown
"""
Decode a line of base64 data.
strict_mode
When set to True, bytes that are not part of the base64 standard are not allowed.
The same applies to excess data after padding (= / ==).
"""
pass这里没东西了,感觉要去翻更底层一点的东西
找到了cPython里面对应的函数binascii_a2b_base64_impl
static PyObject *
binascii_a2b_base64_impl(PyObject *module, Py_buffer *data, int strict_mode)
/*[clinic end generated code: output=5409557788d4f975 input=13c797187acc9c40]*/
{
assert(data->len >= 0);
const unsigned char *ascii_data = data->buf;
size_t ascii_len = data->len;
binascii_state *state = NULL;
char padding_started = 0;
/* Allocate the buffer */
Py_ssize_t bin_len = ((ascii_len+3)/4)*3; /* Upper bound, corrected later */
PyBytesWriter *writer = PyBytesWriter_Create(bin_len);
if (writer == NULL) {
return NULL;
}
unsigned char *bin_data = PyBytesWriter_GetData(writer);
if (strict_mode && ascii_len > 0 && ascii_data[0] == '=') {
state = get_binascii_state(module);
if (state) {
PyErr_SetString(state->Error, "Leading padding not allowed");
}
goto error_end;
}
int quad_pos = 0;
unsigned char leftchar = 0;
int pads = 0;
for (size_t i = 0; i < ascii_len; i++) {
unsigned char this_ch = ascii_data[i];
/* Check for pad sequences and ignore
** the invalid ones.
*/
if (this_ch == BASE64_PAD) {
padding_started = 1;
if (strict_mode && quad_pos == 0) {
state = get_binascii_state(module);
if (state) {
PyErr_SetString(state->Error, "Excess padding not allowed");
}
goto error_end;
}
if (quad_pos >= 2 && quad_pos + ++pads >= 4) {
/* A pad sequence means we should not parse more input.
** We've already interpreted the data from the quad at this point.
** in strict mode, an error should raise if there's excess data after the padding.
*/
if (strict_mode && i + 1 < ascii_len) {
state = get_binascii_state(module);
if (state) {
PyErr_SetString(state->Error, "Excess data after padding");
}
goto error_end;
}
goto done;
}
continue;
}
this_ch = table_a2b_base64[this_ch];
if (this_ch >= 64) {
if (strict_mode) {
state = get_binascii_state(module);
if (state) {
PyErr_SetString(state->Error, "Only base64 data is allowed");
}
goto error_end;
}
continue;
}
// Characters that are not '=', in the middle of the padding, are not allowed
if (strict_mode && padding_started) {
state = get_binascii_state(module);
if (state) {
PyErr_SetString(state->Error, "Discontinuous padding not allowed");
}
goto error_end;
}
pads = 0;
switch (quad_pos) {
case 0:
quad_pos = 1;
leftchar = this_ch;
break;
case 1:
quad_pos = 2;
*bin_data++ = (leftchar << 2) | (this_ch >> 4);
leftchar = this_ch & 0x0f;
break;
case 2:
quad_pos = 3;
*bin_data++ = (leftchar << 4) | (this_ch >> 2);
leftchar = this_ch & 0x03;
break;
case 3:
quad_pos = 0;
*bin_data++ = (leftchar << 6) | (this_ch);
leftchar = 0;
break;
}
}
if (quad_pos != 0) {
state = get_binascii_state(module);
if (state == NULL) {
/* error already set, from get_binascii_state */
assert(PyErr_Occurred());
} else if (quad_pos == 1) {
/*
** There is exactly one extra valid, non-padding, base64 character.
** This is an invalid length, as there is no possible input that
** could encoded into such a base64 string.
*/
unsigned char *bin_data_start = PyBytesWriter_GetData(writer);
PyErr_Format(state->Error,
"Invalid base64-encoded string: "
"number of data characters (%zd) cannot be 1 more "
"than a multiple of 4",
(bin_data - bin_data_start) / 3 * 4 + 1);
} else {
PyErr_SetString(state->Error, "Incorrect padding");
}
goto error_end;
}
done:
return PyBytesWriter_FinishWithPointer(writer, bin_data);
error_end:
PyBytesWriter_Discard(writer);
return NULL;
}主要关注这一段,这一段已经在处理非字符串头出现的padding段了
if (this_ch == BASE64_PAD) {
padding_started = 1;
if (strict_mode && quad_pos == 0) {
state = get_binascii_state(module);
if (state) {
PyErr_SetString(state->Error, "Excess padding not allowed");
}
goto error_end;
}
if (quad_pos >= 2 && quad_pos + ++pads >= 4) {
/* A pad sequence means we should not parse more input.
** We've already interpreted the data from the quad at this point.
** in strict mode, an error should raise if there's excess data after the padding.
*/
if (strict_mode && i + 1 < ascii_len) {
state = get_binascii_state(module);
if (state) {
PyErr_SetString(state->Error, "Excess data after padding");
}
goto error_end;
}
goto done;
}
continue;
}由于不是strict模式我们直接看第三个if
这里判断至少已经读了两个字符并且后续的pad加起来>=4,看似符合了到达base64末尾的条件(但是在严格模式下实则会检测=的后面的是不是还有东西)
那么如果这个字符串本身就是一个带有padding的base64,在非strict模式下就会忽略padding后面的字符从而判断这个base64字符串是合法的
那么如果我们强行加了padding试图瞒天过海呢?
由于此时quad_pos=0,根本进不了出去的循环,就会忽略==,继续做后面有效的字符的解码
也就是说,在宽松情况下对于一个本身没有padding的字符串来说
这个==其实和没加一样。但是当然,如果你尝试在strict模式下这么干,毫无疑问会收获报错。
总结就是,在宽松情况/默认的b64解码中,对于一个含有padding的base64来说,后面可以被塞入任何的数据而python不会做出任何的解码/报错
PHP
php就是直接看C的处理逻辑了
因为PHP好几个版本并且变动比较大的缘故按版本看
5.x
5.x版本的base.c基本上没有啥变动
PHPAPI unsigned char *php_base64_decode_ex(const unsigned char *str, int length, int *ret_length, zend_bool strict) /* {{{ */
{
const unsigned char *current = str;
int ch, i = 0, j = 0, k;
/* this sucks for threaded environments */
unsigned char *result;
result = (unsigned char *)safe_emalloc(length, 1, 1);
/* run through the whole string, converting as we go */
while ((ch = *current++) != '\0' && length-- > 0) {
if (ch == base64_pad) {
if (*current != '=' && ((i % 4) == 1 || (strict && length > 0))) {
if ((i % 4) != 1) {
while (isspace(*(++current))) {
continue;
}
if (*current == '\0') {
continue;
}
}
efree(result);
return NULL;
}
continue;
}
ch = base64_reverse_table[ch];
if ((!strict && ch < 0) || ch == -1) { /* a space or some other separator character, we simply skip over */
continue;
} else if (ch == -2) {
efree(result);
return NULL;
}
switch(i % 4) {
case 0:
result[j] = ch << 2;
break;
case 1:
result[j++] |= ch >> 4;
result[j] = (ch & 0x0f) << 4;
break;
case 2:
result[j++] |= ch >>2;
result[j] = (ch & 0x03) << 6;
break;
case 3:
result[j++] |= ch;
break;
}
i++;
}
k = j;
/* mop things up if we ended on a boundary */
if (ch == base64_pad) {
switch(i % 4) {
case 1:
efree(result);
return NULL;
case 2:
k++;
case 3:
result[k] = 0;
}
}
if(ret_length) {
*ret_length = j;
}
result[j] = '\0';
return result;
}
/* }}} */大致的审计了一下非严格情况下的处理逻辑
当读取的字符的是=会检查padding的位置是否符合规范,不符合就会直接返回空;
遇到非法字符就会直接返回空 遇到\t,\n,\r,空格就会跳过这一轮循环非常的令人安心,找不出什么可以利用的地方
7.0
PHPAPI zend_string *php_base64_decode_ex(const unsigned char *str, size_t length, zend_bool strict) /* {{{ */
{
const unsigned char *current = str;
int ch, i = 0, j = 0, padding = 0;
zend_string *result;
result = zend_string_alloc(length, 0);
/* run through the whole string, converting as we go */
while (length-- > 0) {
ch = *current++;
/* stop on null byte in non-strict mode (FIXME: is this really desired?) */
if (ch == 0 && !strict) {
break;
}
if (ch == base64_pad) {
/* fail if the padding character is second in a group (like V===) */
/* FIXME: why do we still allow invalid padding in other places in the middle of the string? */
if (i % 4 == 1) {
zend_string_free(result);
return NULL;
}
padding++;
continue;
}
ch = base64_reverse_table[ch];
if (!strict) {
/* skip unknown characters and whitespace */
if (ch < 0) {
continue;
}
} else {
/* skip whitespace */
if (ch == -1) {
continue;
}
/* fail on bad characters or if any data follows padding */
if (ch == -2 || padding) {
zend_string_free(result);
return NULL;
}
}
switch(i % 4) {
case 0:
ZSTR_VAL(result)[j] = ch << 2;
break;
case 1:
ZSTR_VAL(result)[j++] |= ch >> 4;
ZSTR_VAL(result)[j] = (ch & 0x0f) << 4;
break;
case 2:
ZSTR_VAL(result)[j++] |= ch >>2;
ZSTR_VAL(result)[j] = (ch & 0x03) << 6;
break;
case 3:
ZSTR_VAL(result)[j++] |= ch;
break;
}
i++;
}
ZSTR_LEN(result) = j;
ZSTR_VAL(result)[ZSTR_LEN(result)] = '\0';
return result;
}7.1-7.2
PHPAPI zend_string *php_base64_decode_ex(const unsigned char *str, size_t length, zend_bool strict) /* {{{ */
{
const unsigned char *current = str;
int ch, i = 0, j = 0, padding = 0;
zend_string *result;
result = zend_string_alloc(length, 0);
/* run through the whole string, converting as we go */
while (length-- > 0) {
ch = *current++;
if (ch == base64_pad) {
padding++;
continue;
}
ch = base64_reverse_table[ch];
if (!strict) {
/* skip unknown characters and whitespace */
if (ch < 0) {
continue;
}
} else {
/* skip whitespace */
if (ch == -1) {
continue;
}
/* fail on bad characters or if any data follows padding */
if (ch == -2 || padding) {
goto fail;
}
}
switch(i % 4) {
case 0:
ZSTR_VAL(result)[j] = ch << 2;
break;
case 1:
ZSTR_VAL(result)[j++] |= ch >> 4;
ZSTR_VAL(result)[j] = (ch & 0x0f) << 4;
break;
case 2:
ZSTR_VAL(result)[j++] |= ch >>2;
ZSTR_VAL(result)[j] = (ch & 0x03) << 6;
break;
case 3:
ZSTR_VAL(result)[j++] |= ch;
break;
}
i++;
}
/* fail if the input is truncated (only one char in last group) */
if (strict && i % 4 == 1) {
goto fail;
}
/* fail if the padding length is wrong (not VV==, VVV=), but accept zero padding
* RFC 4648: "In some circumstances, the use of padding [--] is not required" */
if (strict && padding && (padding > 2 || (i + padding) % 4 != 0)) {
goto fail;
}
ZSTR_LEN(result) = j;
ZSTR_VAL(result)[ZSTR_LEN(result)] = '\0';
return result;
fail:
zend_string_free(result);
return NULL;
}7.3~8.4
static zend_always_inline int php_base64_decode_impl(const unsigned char *in, size_t inl, unsigned char *out, size_t *outl, bool strict) /* {{{ */
{
int ch;
size_t i = 0, padding = 0, j = *outl;
//下面这段在7.3没有
if (inl >= 16 * 4) {
size_t left = 0;
j += neon_base64_decode(in, inl, out, &left);
i = inl - left;
in += i;
inl = left;
}
//
/* run through the whole string, converting as we go */
while (inl-- > 0) {
ch = *in++;
if (ch == base64_pad) {
padding++;
continue;
}
ch = base64_reverse_table[ch];
if (!strict) {
/* skip unknown characters and whitespace */
if (ch < 0) {
continue;
}
} else {
/* skip whitespace */
if (ch == -1) {
continue;
}
/* fail on bad characters or if any data follows padding */
if (ch == -2 || padding) {
goto fail;
}
}
switch (i % 4) {
case 0:
out[j] = ch << 2;
break;
case 1:
out[j++] |= ch >> 4;
out[j] = (ch & 0x0f) << 4;
break;
case 2:
out[j++] |= ch >>2;
out[j] = (ch & 0x03) << 6;
break;
case 3:
out[j++] |= ch;
break;
}
i++;
}
/* fail if the input is truncated (only one char in last group) */
if (strict && i % 4 == 1) {
goto fail;
}
/* fail if the padding length is wrong (not VV==, VVV=), but accept zero padding
* RFC 4648: "In some circumstances, the use of padding [--] is not required" */
if (strict && padding && (padding > 2 || (i + padding) % 4 != 0)) {
goto fail;
}
*outl = j;
out[j] = '\0';
return 1;
fail:
return 0;
}
/* }}} */感觉PHP的逻辑写的比Python的简单的很多
亿眼看下来感觉没有什么大问题,主要的点就是php在非严格模式下=实际就是一个爱加不加的状态。
加不加,加在哪里都不会影响解码,如果是特殊字符就会被直接跳过(因为板子是写好的所以其实就算是其他字符也不能被触发)
Golang
很长的调用链。。好麻烦
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// Package base64 implements base64 encoding as specified by RFC 4648.
package base64
import (
"encoding/binary"
"io"
"slices"
"strconv"
)
/*
* Encodings
*/
// An Encoding is a radix 64 encoding/decoding scheme, defined by a
// 64-character alphabet. The most common encoding is the "base64"
// encoding defined in RFC 4648 and used in MIME (RFC 2045) and PEM
// (RFC 1421). RFC 4648 also defines an alternate encoding, which is
// the standard encoding with - and _ substituted for + and /.
type Encoding struct {
encode [64]byte // mapping of symbol index to symbol byte value
decodeMap [256]uint8 // mapping of symbol byte value to symbol index
padChar rune
strict bool
}
const (
StdPadding rune = '=' // Standard padding character
NoPadding rune = -1 // No padding
)
const (
decodeMapInitialize = "" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff" +
"\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff"
invalidIndex = '\xff'
)
// NewEncoding returns a new padded Encoding defined by the given alphabet,
// which must be a 64-byte string that contains unique byte values and
// does not contain the padding character or CR / LF ('\r', '\n').
// The alphabet is treated as a sequence of byte values
// without any special treatment for multi-byte UTF-8.
// The resulting Encoding uses the default padding character ('='),
// which may be changed or disabled via [Encoding.WithPadding].
func NewEncoding(encoder string) *Encoding {
if len(encoder) != 64 {
panic("encoding alphabet is not 64-bytes long")
}
e := new(Encoding)
e.padChar = StdPadding
copy(e.encode[:], encoder)
copy(e.decodeMap[:], decodeMapInitialize)
for i := 0; i < len(encoder); i++ {
// Note: While we document that the alphabet cannot contain
// the padding character, we do not enforce it since we do not know
// if the caller intends to switch the padding from StdPadding later.
switch {
case encoder[i] == '\n' || encoder[i] == '\r':
panic("encoding alphabet contains newline character")
case e.decodeMap[encoder[i]] != invalidIndex:
panic("encoding alphabet includes duplicate symbols")
}
e.decodeMap[encoder[i]] = uint8(i)
}
return e
}
// WithPadding creates a new encoding identical to enc except
// with a specified padding character, or [NoPadding] to disable padding.
// The padding character must not be '\r' or '\n',
// must not be contained in the encoding's alphabet,
// must not be negative, and must be a rune equal or below '\xff'.
// Padding characters above '\x7f' are encoded as their exact byte value
// rather than using the UTF-8 representation of the codepoint.
func (enc Encoding) WithPadding(padding rune) *Encoding {
switch {
case padding < NoPadding || padding == '\r' || padding == '\n' || padding > 0xff:
panic("invalid padding")
case padding != NoPadding && enc.decodeMap[byte(padding)] != invalidIndex:
panic("padding contained in alphabet")
}
enc.padChar = padding
return &enc
}
// Strict creates a new encoding identical to enc except with
// strict decoding enabled. In this mode, the decoder requires that
// trailing padding bits are zero, as described in RFC 4648 section 3.5.
//
// Note that the input is still malleable, as new line characters
// (CR and LF) are still ignored.
func (enc Encoding) Strict() *Encoding {
enc.strict = true
return &enc
}
// StdEncoding is the standard base64 encoding, as defined in RFC 4648.
var StdEncoding = NewEncoding("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/")
// URLEncoding is the alternate base64 encoding defined in RFC 4648.
// It is typically used in URLs and file names.
var URLEncoding = NewEncoding("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_")
// RawStdEncoding is the standard raw, unpadded base64 encoding,
// as defined in RFC 4648 section 3.2.
// This is the same as [StdEncoding] but omits padding characters.
var RawStdEncoding = StdEncoding.WithPadding(NoPadding)
// RawURLEncoding is the unpadded alternate base64 encoding defined in RFC 4648.
// It is typically used in URLs and file names.
// This is the same as [URLEncoding] but omits padding characters.
var RawURLEncoding = URLEncoding.WithPadding(NoPadding)
/*
* Encoder
*/
// Encode encodes src using the encoding enc,
// writing [Encoding.EncodedLen](len(src)) bytes to dst.
//
// The encoding pads the output to a multiple of 4 bytes,
// so Encode is not appropriate for use on individual blocks
// of a large data stream. Use [NewEncoder] instead.
func (enc *Encoding) Encode(dst, src []byte) {
if len(src) == 0 {
return
}
// enc is a pointer receiver, so the use of enc.encode within the hot
// loop below means a nil check at every operation. Lift that nil check
// outside of the loop to speed up the encoder.
_ = enc.encode
di, si := 0, 0
n := (len(src) / 3) * 3
for si < n {
// Convert 3x 8bit source bytes into 4 bytes
val := uint(src[si+0])<<16 | uint(src[si+1])<<8 | uint(src[si+2])
dst[di+0] = enc.encode[val>>18&0x3F]
dst[di+1] = enc.encode[val>>12&0x3F]
dst[di+2] = enc.encode[val>>6&0x3F]
dst[di+3] = enc.encode[val&0x3F]
si += 3
di += 4
}
remain := len(src) - si
if remain == 0 {
return
}
// Add the remaining small block
val := uint(src[si+0]) << 16
if remain == 2 {
val |= uint(src[si+1]) << 8
}
dst[di+0] = enc.encode[val>>18&0x3F]
dst[di+1] = enc.encode[val>>12&0x3F]
switch remain {
case 2:
dst[di+2] = enc.encode[val>>6&0x3F]
if enc.padChar != NoPadding {
dst[di+3] = byte(enc.padChar)
}
case 1:
if enc.padChar != NoPadding {
dst[di+2] = byte(enc.padChar)
dst[di+3] = byte(enc.padChar)
}
}
}
// AppendEncode appends the base64 encoded src to dst
// and returns the extended buffer.
func (enc *Encoding) AppendEncode(dst, src []byte) []byte {
n := enc.EncodedLen(len(src))
dst = slices.Grow(dst, n)
enc.Encode(dst[len(dst):][:n], src)
return dst[:len(dst)+n]
}
// EncodeToString returns the base64 encoding of src.
func (enc *Encoding) EncodeToString(src []byte) string {
buf := make([]byte, enc.EncodedLen(len(src)))
enc.Encode(buf, src)
return string(buf)
}
type encoder struct {
err error
enc *Encoding
w io.Writer
buf [3]byte // buffered data waiting to be encoded
nbuf int // number of bytes in buf
out [1024]byte // output buffer
}
func (e *encoder) Write(p []byte) (n int, err error) {
if e.err != nil {
return 0, e.err
}
// Leading fringe.
if e.nbuf > 0 {
var i int
for i = 0; i < len(p) && e.nbuf < 3; i++ {
e.buf[e.nbuf] = p[i]
e.nbuf++
}
n += i
p = p[i:]
if e.nbuf < 3 {
return
}
e.enc.Encode(e.out[:], e.buf[:])
if _, e.err = e.w.Write(e.out[:4]); e.err != nil {
return n, e.err
}
e.nbuf = 0
}
// Large interior chunks.
for len(p) >= 3 {
nn := len(e.out) / 4 * 3
if nn > len(p) {
nn = len(p)
nn -= nn % 3
}
e.enc.Encode(e.out[:], p[:nn])
if _, e.err = e.w.Write(e.out[0 : nn/3*4]); e.err != nil {
return n, e.err
}
n += nn
p = p[nn:]
}
// Trailing fringe.
copy(e.buf[:], p)
e.nbuf = len(p)
n += len(p)
return
}
// Close flushes any pending output from the encoder.
// It is an error to call Write after calling Close.
func (e *encoder) Close() error {
// If there's anything left in the buffer, flush it out
if e.err == nil && e.nbuf > 0 {
e.enc.Encode(e.out[:], e.buf[:e.nbuf])
_, e.err = e.w.Write(e.out[:e.enc.EncodedLen(e.nbuf)])
e.nbuf = 0
}
return e.err
}
// NewEncoder returns a new base64 stream encoder. Data written to
// the returned writer will be encoded using enc and then written to w.
// Base64 encodings operate in 4-byte blocks; when finished
// writing, the caller must Close the returned encoder to flush any
// partially written blocks.
func NewEncoder(enc *Encoding, w io.Writer) io.WriteCloser {
return &encoder{enc: enc, w: w}
}
// EncodedLen returns the length in bytes of the base64 encoding
// of an input buffer of length n.
func (enc *Encoding) EncodedLen(n int) int {
if enc.padChar == NoPadding {
return n/3*4 + (n%3*8+5)/6 // minimum # chars at 6 bits per char
}
return (n + 2) / 3 * 4 // minimum # 4-char quanta, 3 bytes each
}
/*
* Decoder
*/
type CorruptInputError int64
func (e CorruptInputError) Error() string {
return "illegal base64 data at input byte " + strconv.FormatInt(int64(e), 10)
}
// decodeQuantum decodes up to 4 base64 bytes. The received parameters are
// the destination buffer dst, the source buffer src and an index in the
// source buffer si.
// It returns the number of bytes read from src, the number of bytes written
// to dst, and an error, if any.
func (enc *Encoding) decodeQuantum(dst, src []byte, si int) (nsi, n int, err error) {
// Decode quantum using the base64 alphabet
var dbuf [4]byte
dlen := 4
// Lift the nil check outside of the loop.
_ = enc.decodeMap
for j := 0; j < len(dbuf); j++ {
if len(src) == si {
switch {
case j == 0:
return si, 0, nil
case j == 1, enc.padChar != NoPadding:
return si, 0, CorruptInputError(si - j)
}
dlen = j
break
}
in := src[si]
si++
out := enc.decodeMap[in]
if out != 0xff {
dbuf[j] = out
continue
}
if in == '\n' || in == '\r' {
j--
continue
}
if rune(in) != enc.padChar {
return si, 0, CorruptInputError(si - 1)
}
// We've reached the end and there's padding
switch j {
case 0, 1:
// incorrect padding
return si, 0, CorruptInputError(si - 1)
case 2:
// "==" is expected, the first "=" is already consumed.
// skip over newlines
for si < len(src) && (src[si] == '\n' || src[si] == '\r') {
si++
}
if si == len(src) {
// not enough padding
return si, 0, CorruptInputError(len(src))
}
if rune(src[si]) != enc.padChar {
// incorrect padding
return si, 0, CorruptInputError(si - 1)
}
si++
}
// skip over newlines
for si < len(src) && (src[si] == '\n' || src[si] == '\r') {
si++
}
if si < len(src) {
// trailing garbage
err = CorruptInputError(si)
}
dlen = j
break
}
// Convert 4x 6bit source bytes into 3 bytes
val := uint(dbuf[0])<<18 | uint(dbuf[1])<<12 | uint(dbuf[2])<<6 | uint(dbuf[3])
dbuf[2], dbuf[1], dbuf[0] = byte(val>>0), byte(val>>8), byte(val>>16)
switch dlen {
case 4:
dst[2] = dbuf[2]
dbuf[2] = 0
fallthrough
case 3:
dst[1] = dbuf[1]
if enc.strict && dbuf[2] != 0 {
return si, 0, CorruptInputError(si - 1)
}
dbuf[1] = 0
fallthrough
case 2:
dst[0] = dbuf[0]
if enc.strict && (dbuf[1] != 0 || dbuf[2] != 0) {
return si, 0, CorruptInputError(si - 2)
}
}
return si, dlen - 1, err
}
// AppendDecode appends the base64 decoded src to dst
// and returns the extended buffer.
// If the input is malformed, it returns the partially decoded src and an error.
// New line characters (\r and \n) are ignored.
func (enc *Encoding) AppendDecode(dst, src []byte) ([]byte, error) {
// Compute the output size without padding to avoid over allocating.
n := len(src)
for n > 0 && rune(src[n-1]) == enc.padChar {
n--
}
n = decodedLen(n, NoPadding)
dst = slices.Grow(dst, n)
n, err := enc.Decode(dst[len(dst):][:n], src)
return dst[:len(dst)+n], err
}
// DecodeString returns the bytes represented by the base64 string s.
// If the input is malformed, it returns the partially decoded data and
// [CorruptInputError]. New line characters (\r and \n) are ignored.
func (enc *Encoding) DecodeString(s string) ([]byte, error) {
dbuf := make([]byte, enc.DecodedLen(len(s)))
n, err := enc.Decode(dbuf, []byte(s))
return dbuf[:n], err
}
type decoder struct {
err error
readErr error // error from r.Read
enc *Encoding
r io.Reader
buf [1024]byte // leftover input
nbuf int
out []byte // leftover decoded output
outbuf [1024 / 4 * 3]byte
}
func (d *decoder) Read(p []byte) (n int, err error) {
// Use leftover decoded output from last read.
if len(d.out) > 0 {
n = copy(p, d.out)
d.out = d.out[n:]
return n, nil
}
if d.err != nil {
return 0, d.err
}
// This code assumes that d.r strips supported whitespace ('\r' and '\n').
// Refill buffer.
for d.nbuf < 4 && d.readErr == nil {
nn := len(p) / 3 * 4
if nn < 4 {
nn = 4
}
if nn > len(d.buf) {
nn = len(d.buf)
}
nn, d.readErr = d.r.Read(d.buf[d.nbuf:nn])
d.nbuf += nn
}
if d.nbuf < 4 {
if d.enc.padChar == NoPadding && d.nbuf > 0 {
// Decode final fragment, without padding.
var nw int
nw, d.err = d.enc.Decode(d.outbuf[:], d.buf[:d.nbuf])
d.nbuf = 0
d.out = d.outbuf[:nw]
n = copy(p, d.out)
d.out = d.out[n:]
if n > 0 || len(p) == 0 && len(d.out) > 0 {
return n, nil
}
if d.err != nil {
return 0, d.err
}
}
d.err = d.readErr
if d.err == io.EOF && d.nbuf > 0 {
d.err = io.ErrUnexpectedEOF
}
return 0, d.err
}
// Decode chunk into p, or d.out and then p if p is too small.
nr := d.nbuf / 4 * 4
nw := d.nbuf / 4 * 3
if nw > len(p) {
nw, d.err = d.enc.Decode(d.outbuf[:], d.buf[:nr])
d.out = d.outbuf[:nw]
n = copy(p, d.out)
d.out = d.out[n:]
} else {
n, d.err = d.enc.Decode(p, d.buf[:nr])
}
d.nbuf -= nr
copy(d.buf[:d.nbuf], d.buf[nr:])
return n, d.err
}
// Decode decodes src using the encoding enc. It writes at most
// [Encoding.DecodedLen](len(src)) bytes to dst and returns the number of bytes
// written. The caller must ensure that dst is large enough to hold all
// the decoded data. If src contains invalid base64 data, it will return the
// number of bytes successfully written and [CorruptInputError].
// New line characters (\r and \n) are ignored.
func (enc *Encoding) Decode(dst, src []byte) (n int, err error) {
if len(src) == 0 {
return 0, nil
}
// Lift the nil check outside of the loop. enc.decodeMap is directly
// used later in this function, to let the compiler know that the
// receiver can't be nil.
_ = enc.decodeMap
si := 0
for strconv.IntSize >= 64 && len(src)-si >= 8 && len(dst)-n >= 8 {
src2 := src[si : si+8]
if dn, ok := assemble64(
enc.decodeMap[src2[0]],
enc.decodeMap[src2[1]],
enc.decodeMap[src2[2]],
enc.decodeMap[src2[3]],
enc.decodeMap[src2[4]],
enc.decodeMap[src2[5]],
enc.decodeMap[src2[6]],
enc.decodeMap[src2[7]],
); ok {
binary.BigEndian.PutUint64(dst[n:], dn)
n += 6
si += 8
} else {
var ninc int
si, ninc, err = enc.decodeQuantum(dst[n:], src, si)
n += ninc
if err != nil {
return n, err
}
}
}
for len(src)-si >= 4 && len(dst)-n >= 4 {
src2 := src[si : si+4]
if dn, ok := assemble32(
enc.decodeMap[src2[0]],
enc.decodeMap[src2[1]],
enc.decodeMap[src2[2]],
enc.decodeMap[src2[3]],
); ok {
binary.BigEndian.PutUint32(dst[n:], dn)
n += 3
si += 4
} else {
var ninc int
si, ninc, err = enc.decodeQuantum(dst[n:], src, si)
n += ninc
if err != nil {
return n, err
}
}
}
for si < len(src) {
var ninc int
si, ninc, err = enc.decodeQuantum(dst[n:], src, si)
n += ninc
if err != nil {
return n, err
}
}
return n, err
}
// assemble32 assembles 4 base64 digits into 3 bytes.
// Each digit comes from the decode map, and will be 0xff
// if it came from an invalid character.
func assemble32(n1, n2, n3, n4 byte) (dn uint32, ok bool) {
// Check that all the digits are valid. If any of them was 0xff, their
// bitwise OR will be 0xff.
if n1|n2|n3|n4 == 0xff {
return 0, false
}
return uint32(n1)<<26 |
uint32(n2)<<20 |
uint32(n3)<<14 |
uint32(n4)<<8,
true
}
// assemble64 assembles 8 base64 digits into 6 bytes.
// Each digit comes from the decode map, and will be 0xff
// if it came from an invalid character.
func assemble64(n1, n2, n3, n4, n5, n6, n7, n8 byte) (dn uint64, ok bool) {
// Check that all the digits are valid. If any of them was 0xff, their
// bitwise OR will be 0xff.
if n1|n2|n3|n4|n5|n6|n7|n8 == 0xff {
return 0, false
}
return uint64(n1)<<58 |
uint64(n2)<<52 |
uint64(n3)<<46 |
uint64(n4)<<40 |
uint64(n5)<<34 |
uint64(n6)<<28 |
uint64(n7)<<22 |
uint64(n8)<<16,
true
}
type newlineFilteringReader struct {
wrapped io.Reader
}
func (r *newlineFilteringReader) Read(p []byte) (int, error) {
n, err := r.wrapped.Read(p)
for n > 0 {
offset := 0
for i, b := range p[:n] {
if b != '\r' && b != '\n' {
if i != offset {
p[offset] = b
}
offset++
}
}
if offset > 0 {
return offset, err
}
// Previous buffer entirely whitespace, read again
n, err = r.wrapped.Read(p)
}
return n, err
}
// NewDecoder constructs a new base64 stream decoder.
func NewDecoder(enc *Encoding, r io.Reader) io.Reader {
return &decoder{enc: enc, r: &newlineFilteringReader{r}}
}
// DecodedLen returns the maximum length in bytes of the decoded data
// corresponding to n bytes of base64-encoded data.
func (enc *Encoding) DecodedLen(n int) int {
return decodedLen(n, enc.padChar)
}
func decodedLen(n int, padChar rune) int {
if padChar == NoPadding {
// Unpadded data may end with partial block of 2-3 characters.
return n/4*3 + n%4*6/8
}
// Padded base64 should always be a multiple of 4 characters in length.
return n / 4 * 3
}
调试了一下给出调用链
DecodeString
DecodeLen
decodedLen
Decode(dst,src[] byte)
assemble64
assemble32
decodeQuantum后面吃不明白了。go没怎么学过,有兴趣的师傅可以拿去瞅一眼。有可以trick的利用点欢迎跟我交流一下(
Java
学了java再来审(
Ruby
一整个项目看不了一一点
Linux
// SPDX-License-Identifier: GPL-2.0
/*
* base64.c - RFC4648-compliant base64 encoding
*
* Copyright (c) 2020 Hannes Reinecke, SUSE
*
* Based on the base64url routines from fs/crypto/fname.c
* (which are using the URL-safe base64 encoding),
* modified to use the standard coding table from RFC4648 section 4.
*/
static const char base64_table[65] =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
/**
* base64_encode() - base64-encode some binary data
* @src: the binary data to encode
* @srclen: the length of @src in bytes
* @dst: (output) the base64-encoded string. Not NUL-terminated.
*
* Encodes data using base64 encoding, i.e. the "Base 64 Encoding" specified
* by RFC 4648, including the '='-padding.
*
* Return: the length of the resulting base64-encoded string in bytes.
*/
int base64_encode(const u8 *src, int srclen, char *dst)
{
u32 ac = 0;
int bits = 0;
int i;
char *cp = dst;
for (i = 0; i < srclen; i++) {
ac = (ac << 8) | src[i];
bits += 8;
do {
bits -= 6;
*cp++ = base64_table[(ac >> bits) & 0x3f];
} while (bits >= 6);
}
if (bits) {
*cp++ = base64_table[(ac << (6 - bits)) & 0x3f];
bits -= 6;
}
while (bits < 0) {
*cp++ = '=';
bits += 2;
}
return cp - dst;
}
EXPORT_SYMBOL_GPL(base64_encode);
/**
* base64_decode() - base64-decode a string
* @src: the string to decode. Doesn't need to be NUL-terminated.
* @srclen: the length of @src in bytes
* @dst: (output) the decoded binary data
*
* Decodes a string using base64 encoding, i.e. the "Base 64 Encoding"
* specified by RFC 4648, including the '='-padding.
*
* This implementation hasn't been optimized for performance.
*
* Return: the length of the resulting decoded binary data in bytes,
* or -1 if the string isn't a valid base64 string.
*/
int base64_decode(const char *src, int srclen, u8 *dst)
{
u32 ac = 0;
int bits = 0;
int i;
u8 *bp = dst;
for (i = 0; i < srclen; i++) {
const char *p = strchr(base64_table, src[i]);
if (src[i] == '=') {
ac = (ac << 6);
bits += 6;
if (bits >= 8)
bits -= 8;
continue;
}
if (p == NULL || src[i] == 0)
return -1;
ac = (ac << 6) | (p - base64_table);
bits += 6;
if (bits >= 8) {
bits -= 8;
*bp++ = (u8)(ac >> bits);
}
}
if (ac & ((1 << bits) - 1))
return -1;
return bp - dst;
}
EXPORT_SYMBOL_GPL(base64_decode);这里的padding也是几乎不会出什么大的问题,而且默认严格模式,包正经base64的
不喜欢看这个。。看着就感觉眼皮重了啊,但是还好最后基本都啃下来了(除了实在啃不了的)
本人也是臭菜鸟,哪里有分析的不到位的或者有哪里没分析出来的欢迎师傅加我QQ一起讨论!!